Asynchronous Schema Change
介绍
F1 是 Google 开发的分布式 SQL 引擎,主要有五个特性:大规模分布式、关系型模型、共享数据存储、无状态服务器、无全局领导。要在这套系统上实现 schema 变更,此在设计上存在一些局限性:
- 数据可用性:在 Schema change 的过程中,不能容忍有数据处于离线状态
- 低性能影响:由于 Schema change 比较频繁,因此这个操作不能对使用者的响应时间造成过多的影响
- 异步变更:由于不存在全局的 leader 将变化同步到所有服务器上,因此同一个时间点上不同的服务器可能处于不同的状态
因此,在设计上不仅要考虑到添加/删除列、索引,还要保证这些修改不需要显式的节点同步。
一个简单的例子
假设一个客户端为表 $R$ 增加了索引 $I$,schema 从 $S_1$ 变为了 $S_2$,同时,存在两个不同的服务器 $M_1$ 和 $M_2$
- $M_2$ 当前使用的是 $S_2$,同时它向 $R$ 写入了一行新数据 $r$,由于 $S_2$ 包含了新索引的信息,因此这条语句会同时在这个索引 $I$ 中写入一条记录。
- $M_1$ 当前使用的是 $S_1$,执行了删除 $r$ 的操作,由于 $S_1$ 没有感知到 $I$ 的存在,因此该索引并没有被修改。
这就导致了数据错误,当后续需要执行 Index-only scan 的时候,就会读取到已经被删除的行。
底层抽象
键值存储
F1 的底层是一个分布式的 kv 数据库,提供了 put、get 和 del 三个接口。由于使用了乐观并发控制,因此每个键值对数据都包含一个 last-modified timestamp,同时多个 get 和 put 请求可以原子执行。
表结构定义
一个 F1 schema 是一组表定义(Table definition)的组合,每个表定义包含了一组列、二级索引、完整性约束(唯一性、外键)以及乐观锁。如果某一列要求必须提供一个值,称其为 required(例如主键列),反之则称为 optimal。
- 每一列数据都被表示为一组键值对数据,每个都对应了一个非主键列,完成由
表名-主键值-列名到列值的映射,这里将 $r$ 在列 $C$ 上的 key 记为 $k_r(C)$ - 除此之外,每一行还存储了一个特殊的键值对
表名-主键值-exists,判断该行是否存在 - 对于索引 $I$ 来说,记录的是
表名-索引名-列值-主键值,记为 $k_r(I)$
下图就是一个示例

F1 支持如下四类的操作:
- $insert_S^{T_i}(R, vk_r, vc_r)$:事务 $T_i$ 根据当前的 schema $S$(下同),将 $r$ 写入 $R$ 中,其中主键值和非主键值分别为 $vk_r$ 和 $vc_r$
- $delete_S^{T_i}(R, vk_r)$:使用主键进行删除,包括了数据、索引等
- $update_S^{T_i}(R, vk_r, vc_r)$:找到主键值为 $vk_r$ 的行,将部分非主键值修改为 $vc_r$,如果想要修改主键值,只能通过删除加插入的操作
- $query(\vec{R}, \vec{C}, P)$:查询操作
为了简化描述,使用 $query(R, C, vk_r)$ 表示在 $R$ 读取主键值为 $vk_r$ 的行的 $C$ 列值
并发控制
F1 使用基于时间戳的乐观并发控制,锁同样存储在 schema 中,每个表可能存在多个锁,但是每一列只能被一个乐观锁覆盖。
当用户读取了一部分列值时,会从覆盖着这些列的所有锁中记录 last-modified timestamp,以在事务提交的时候进行校验,如果成功提交则会修改相应的时间戳。
F1 默认的锁粒度是行级别,也就是每一行还有一个默认的大锁来控制这行的所有列,用户也可以自己指定锁粒度,使用表级别的列锁控制访问。
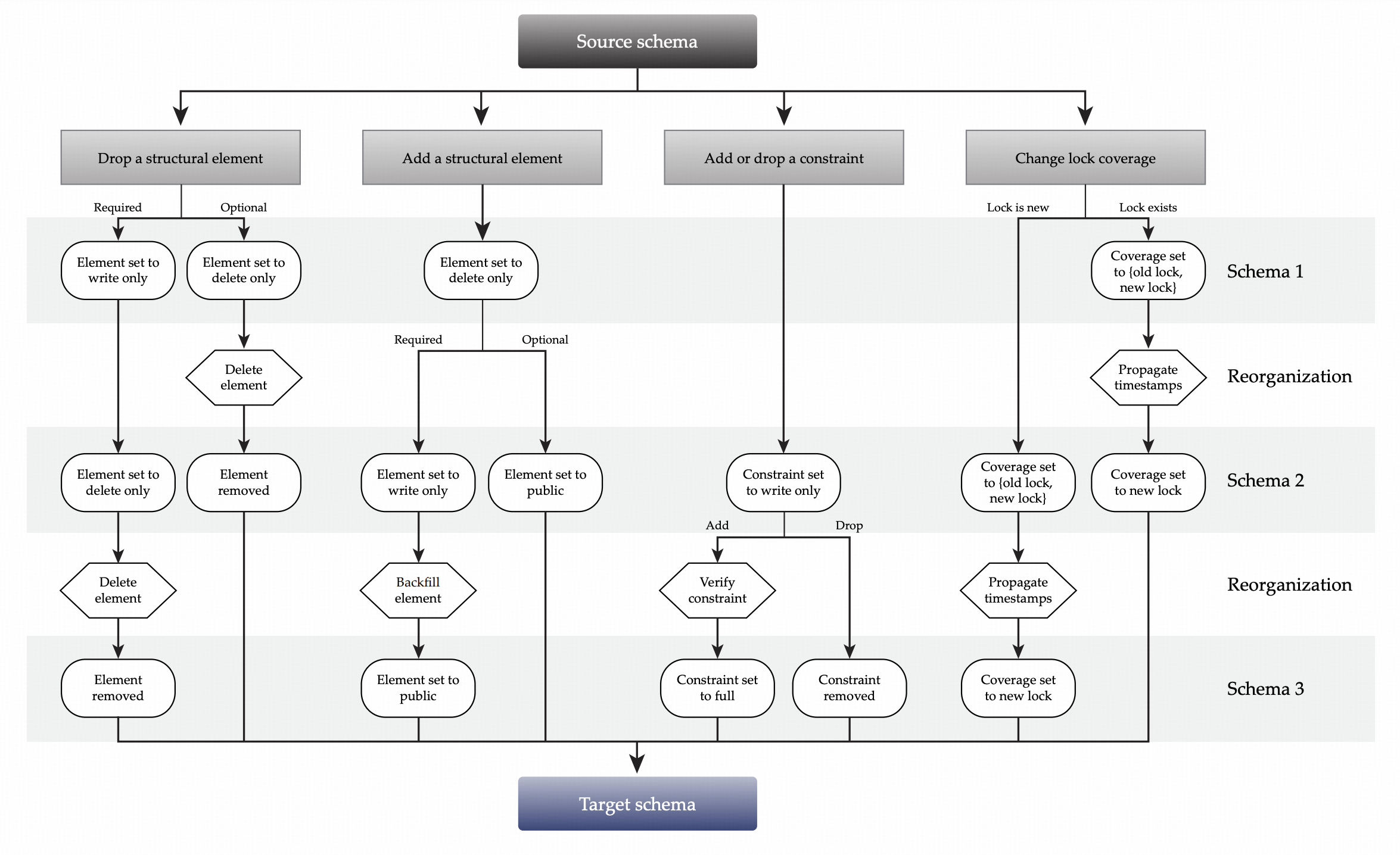
异步 Schema 变更
直接进行 Schema 变更的问题在于前后的两个状态之间并不兼容,或者说,两个版本包含的信息差异过大,导致同一个操作无法同时同时应用。为了避免这种情况,论文提出了中间状态(intermediate states),将原本的 schema 变更拆分为了小粒度的变化,每个中间状态都会限制当前可以应用的操作,以保证操作的安全性。
为了简化算法正确性的证明,论文作出了一个限制:所有的 F1 实例至多使用两个不同的 schema 版本,也就是说每个服务器要么使用最新的 schema,要么使用旧一个版本的 schema。
基本定义
由于所有的 F1 实例共享底层存储的数据,这里将所有数据的集合称为 database representation,后续全部用 $d$ 表示。
每个 schema (缩写为 $S$ )所包含的每个信息(列、索引、锁等等)都被称为元素(element),每个元素可能处在以下四种状态之一:
- absent:如果某个元素不在当前的 schema 中,那它就是 absent 的。
- public:这个状态和 absent 相反。
- delete-only:一个 delete-only 的元素对用户事务是不可见的;如果 $E$ 是表,那么它只能被 $delete$ 操作处理;如果 $E$ 是索引,那么它只能被 $delete$ 和 $update$ 操作处理(这里的 $update$ 操作中,只能删除对应的键值对数据,而不能创建新的键值对)。
- write-only:
- 一个 write-only 的表或索引可以被 $insert$、$update$、$delete$ 操作处理,但是它们的数据对用户是不可见的;
- 一个 write-only 的 constraint 会被应用在所有新的操作上,但是并不能现存数据满足该约束。
数据一致性
P.S. 这一节的内容还是有点抽象的,可以结合原论文一起看。
首先定义数据一致性的概念:
定义:若 $d$ 和 $S$ 满足如下条件,则称为 $d$ 和 $S$ 满足数据一致性,记为 $d \models S$:
- 对于任意一个非主键列数据 $\langle k_r(C), v_r(C) \rangle$,必须存在对应的 $\langle k_r(exists),null\rangle$ ,同时存在表 $R \in S$ 包含列 $C$
- 对于每个 public 列 $C \in R \in S$,如果存在 $\langle k_r(exists),null\rangle$ 记录,那么必须存在对应的 $\langle k_r(C), v_r(C) \rangle$ 记录
- 对于每个索引项 $\langle k_r(I),null\rangle$ 记录,必须存在表 $R\in S$ 包含 $I$
- 对于每个索引 $I$,那么每一行 $r \in R$ 都必须存在索引项 $\langle k_r(I), null \rangle$
- 对于每个索引项 $\langle k_r(I),null\rangle$ 记录以及 $I$ 中包含的每个列 $C$,必须存在对应的 $\langle k_r(C), v_r(C) \rangle$
- $d$ 中所有的键值对数据都满足 $S$ 包含的所有约束,约束所要求的所有键值对都必须存在
- 没有除了条件1和3假定范围以外的键值对数据
条件看上去很多,但其实细分一下就分为两类:
- $d$ 中包含了一些不属于 $S$ 的数据,即违反了1、3、5、7,称之为孤立数据异常,
- $d$ 中缺失了一些 $S$ 本该包含的数据,或者 $d$ 中存在一些违反了约束的数据,称之为完整性异常
基于这个定义,这里提出了保一致性变换(consistency-preserving schema change)的概念
定义:一个从 $S_1$ 变为 $S_2$ 的变换是保一致性的,当且仅当
- 任何基于 $S1$ 进行的操作 $op{s_1}$ 不会破坏 $d$ 和 $S_2$ 之间的一致性
- 任何基于 $S2$ 进行的操作 $op{s_2}$ 不会破坏 $d$ 和 $S_1$ 之间的一致性
第一条要求是比较显然的,因为我们是从 $S_1$ 变更到 $S_2$,然而第二条乍看之下可能没什么必要,因为所有的服务器最终都会同步到 $S_2$ 的状态,然而事实上 $S_1$ 产生的不一致问题可能也会反过来影响到 $S_2$,例如下面的例子:
- 假设某一次变更添加了一列 $C$,初始状态时 $d \models S_2$。
- 首先 $S_2$ 执行了一条 $insert(R, vk_r, vr(C))$ 操作,写入了一个新的键值对 $\langle k_r(C), v_r(C) \rangle$。
- 随后 $S_1$ 又执行了操作 $delete(R, vk_r)$,这个操作并不会删除 $\langle k_r(C), v_r(C) \rangle$。
- 因此此时 $d^\prime$ 和 $S_2$ 的一致性被破坏了,使得基于 $S_2$ 的 index only scan 得到错误的结果。
可以看出在保一致性变换中,基于不同版本的修改都不会影响数据一致性,因此也能得到如下结论:
Claim 1. $S_1$ 到 $S_2$ 的变换是保一致性的当且仅当 $S_2$ 到 $S_1$ 的变换也是保一致性的。
添加/删除 Schema 元素
根据上面的例子可以看出,直接在 schema 中添加或删除元素很有可能是不安全的,无论添加的是表、列、还是索引,都能很容易的找出一个例子,这也是得到了结论2
Claim 2:任何涉及添加/删除 public 元素的操作都不能保证一致性。
Claim 3:$S_1$ 到 $S_2$ 的变换是保一致性的当且仅当该变化能够避免孤立数据异常和完整性异常
Optional 元素
当涉及 Optional 元素的修改时,为了避免上述问题,可以通过为元素添加一个 delete-only 的中间状态来消除这些问题,下面来证明这种方式的正确性。
Claim 4. 假设 $S_1$ 通过添加一个 delete-only 的元素 $E$ 变为 $S_2$,则对于任何满足 $d \models S_1$ 的 $d$,它一定满足 $d \models S2$,并且任意作用于 $d$ 的 $op{s1}$ 和 $op{S_2}$ 都不会破坏对 $S_1$ 和 $S_2$ 的一致性。(注意这里不要求 optional)
证明:
- 由于 $d \models S_1$,因此 $d$ 中不会包含任何和 $E$ 有关的数据,同时由于 $E$ 对于 $S_2$ 是非 public 的,因此不需要额外的数据来满足 $d$ 和 $S_2$ 的完整性。
- 对 $S_1$ 和 $S_2$ 的任何操作都不会为 $E$ 创建数据,显然不会产生多余数据,因此不会破坏完整性。
Claim 5. 假设 $S_1$ 通过将 optional 元素从 delete-only 提升至 public 变为 $S_2$,则对于任何满足 $d \models S_1$ 的 $d$,它一定满足 $d \models S2$,并且任意作用于 $d$ 的 $op{s1}$ 和 $op{S_2}$ 都不会破坏对 $S_1$ 和 $S_2$ 的完整性。
证明:
- 由于 $d \models S_1$,并且 $E$ 是 delete-only 的,因此 $d$ 中可能存在或不存在与 $E$ 相关的数据;不过由于 $E$ 是 optional 的,这些存在的数据不会影响 $S_2$ 的完整性,因此 $d \models S_2$。
- $op_{S1}$ 和 $op{S_2}$ 都会删除 $d$ 中和 $E$ 有关的数据,因此删除操作不会影响完整性;此外根据第一点,插入操作同样不会影响完整性。
因此,如果一个元素是 optional 的,那么可以通过如下的流程实现安全的变更(对于删除元素来说,顺序相反):
$$
absent → delete only → public
$$
Required 元素
对于 required 元素来说,上面的流程显然不能满足完整性要求,可以很简单地找到破坏 delete-only 到 public 完整性的例子,因此这里加入了额外的步骤:
$$
absent \rightarrow delete only \rightarrow write only \rightarrow^{db reorg} public
$$
Claim 6. 假设 $S_1$ 通过将一个索引或 required 列从 delete-only 提升为 write-only 变为了 $S_2$,则对于任何满足 $d \models S_1$ 的 $d$,它一定满足 $d \models S2$,并且任意作用于 $d$ 的 $op{s1}$ 和 $op{S_2}$ 都不会破坏对 $S_1$ 和 $S_2$ 的完整性
证明:
- 因为 $E$ 对于 $S_1$ 和 $S_2$ 都可见,因此两者都允许存在和 $E$ 有关的数据,同时由于 $E$ 对两者都不是 public 的,因此这些数据不会影响完整性,即 $d \models S_1, S_2$
- 以索引为例:
- 能够导致孤儿数据的只有条件3和5,两者的发生都基于一个前提,即存在孤儿数据 $\langle k_r(I),null\rangle$,由于这个数据只会由 delete 或 update 操作产生,而 $S_1$ 和 $S_2$ 都允许删除数据,因此不可能发生这种情况。
- 同时由于 $E$ 对两者都不是 public 的,因此数据完整性不可能被破坏。
一旦某个元素被转换为了 write-only 状态,新数据就可以被有效处理,然而,schema 变更前的数据可能还没有同步(例如索引数据),因此在提升为 public 前,必须执行 data reorganization 过程来填补所有的空缺值,
Claim 7. 假设 $S_1$ 通过将元素 $E$ 从 write-only 提升为 public 变为了 $S_2$,对于任何满足 $d \models S_1,S2$ 的 $d$,任意作用于 $d$ 的 $op{s1}$ 和 $op{S_2}$ 都不会破坏对 $S_1$ 和 $S_2$ 的完整性
证明:
- 和 Claim6 类似,由于两个状态均支持删除操作,因此一定不会存在孤儿数据。
- 而对于数据完整性来说,如果 $E$ 是 optional 的,不要求完整性,反之,与 $E$ 相关的数据必然会被更新,因此不会存在数据完整性问题。
Theorem 1. 考虑 $S_1$ 通过添加或删除元素 $E$ 变为了 $S_2$,对于任何满足 $d_1 \models S_1$ 的 $d_1$,存在一个保一致性的变换流程,保证在通过至多一次 reorganization 后,能够将所有服务器的 schema 变为 $S_2$,并且得到一个满足 $d_2 \models S_2$ 的 $d$
约束修改
F1 支持的约束为唯一性约束和主外键,皆可通过下面的方式实现安全变更,证明略。
$$
absent → write only → public
$$
修改锁覆盖范围
锁变更看上去和 Schema 变化没啥关系,但是由于在 F1 里锁也是一个对象,用户可以通过修改乐观来改变锁定的列,因此锁变更和添加/删除列可以看作是一样的。
锁定覆盖模式的变更会修改哪个锁来控制给定列的并发性。请注意,锁定的删除会隐式地导致相应的锁定覆盖变更,因为所有列必须由某个锁来覆盖。如果锁定覆盖的变更实施不当,可能会允许非序列化的调度。
Chaim 8:A schema change from schema S1 to S2 which changes the coverage of column C from lock L1 to lock L2 allows non-serializable schedules.
证明:
- 假设存在两个事务 $T_i$ 和 $Tj$,以如下顺序执行:$query{S_1}^{i}(R, C, vkr) \rightarrow write{S_2}^{j}(R, vk_r, vr(C))\rightarrow write{S_1}^{i}(R, vk_r, v_r(C))$
- 这里存在一个读写冲突,但是由于 $T_1$ 更新的是 $L_1$ 的时间戳,$T_2$ 更新的是 $L_2$ 的时间戳,两者都能成功提交。
为了解决这个问题,系统允许同一列暂时被多个锁覆盖,当把某个列的锁换成另一个时,需要插入一个中间状态,该状态下该列会同时被旧锁和新锁覆盖,所有操作都必须同时读取和验证这两把锁。然而,这种模式变更的组合仍然允许出现非序列化的调度。
假设在 $S_1$ 中, $C$ 被 $L_1$ 覆盖,在 $S_2$ 中,$L_1$ 和 $L_2$ 都覆盖了该列,最后转变为 $S_3$ 中 $C$ 被 $L_2$ 覆盖,且 $L_1$ 和 $L_2$ 具有相同的时间戳 $t1$,考虑如下流程
$$
query{S_1}^{i}(R, C, vkr) \rightarrow write{S_1}^{j}(R, vk_r, vr(C))\rightarrow write{S_3}^{i}(R, vk_r, v_r(C))
$$
尽管 $T_j$ 已经通过提交修改了 $S_1$ 下的时间戳,但是 $T_i$ 提交的时候是通过 $S_3$ 进行验证的,依然能成功提交。
因此,在所有服务器完成了 schema 变更后,需要更新新锁的时间戳:
$$
timestamp(L_2) = \max(timestamp(L_1), timestamp(L_2))
$$
这一个部分感觉更抽象了,确实没太理解为啥这么处理就能解决问题
实现

{kind=link}
Schema lease
F1 要求所有服务器同时使用最多两个不同的 schema,为了在无主状态下解决这个问题,引入了租期(Schema lease),所有的 F1 服务器每隔一个租期就会从一个固定的服务器读取最新的 schema,并刷新租期,如果服务器无法刷新租期,它会被终止。
用户事务可以跨越多个租期,但是写操作只能基于最新租期内的 schema 进行,因为如果写操作的执行时间超过两个租期,会违反前提条件,因此 F1 使用 write fencing 来保证基于过期租约的写操作无法提交(底层的 Spanner 能够拒绝超过给定时间戳的写入请求)
总结
F1 的这套框架虽然证明很复杂,实际的操作其实还是比较好懂的,给出了一套很不错的理论。TiDB 内部也是基于这套框架去实现的,不过在很多方面都有所变化,这个等我全部看懂了再说吧。
下几篇读的应该是 NSDI24 的 sieve、VLDB21 的 corobase、和 VLDB24 的 The Art of Latency Hiding in Modern Database Engines